A Power Law Keeps the Brain’s Perceptions Balanced

New research shows that patterns of neural activity are as detailed, or high-dimensional, as they can possibly be without becoming fractal, or non-smooth.
Introduction
The human brain is often described in the language of tipping points: It toes a careful line between high and low activity, between dense and sparse networks, between order and disorder. Now, by analyzing firing patterns from a record number of neurons, researchers have uncovered yet another tipping point — this time, in the neural code, the mathematical relationship between incoming sensory information and the brain’s neural representation of that information. Their findings, published in Nature in June, suggest that the brain strikes a balance between encoding as much information as possible and responding flexibly to noise, which allows it to prioritize the most significant features of a stimulus rather than endlessly cataloging smaller details. The way it accomplishes this feat could offer fresh insights into how artificial intelligence systems might work, too.
A balancing act is not what the scientists initially set out to find. Their work began with a simpler question: Does the visual cortex represent various stimuli with many different response patterns, or does it use similar patterns over and over again? Researchers refer to the neural activity in the latter scenario as low-dimensional: The neural code associated with it would have a very limited vocabulary, but it would also be resilient to small perturbations in sensory inputs. Imagine a one-dimensional code in which a stimulus is simply represented as either good or bad. The amount of firing by individual neurons might vary with the input, but the neurons as a population would be highly correlated, their firing patterns always either increasing or decreasing together in the same overall arrangement. Even if some neurons misfired, a stimulus would most likely still get correctly labeled.
At the other extreme, high-dimensional neural activity is far less correlated. Since information can be graphed or distributed across many dimensions, not just along a few axes like “good-bad,” the system can encode far more detail about a stimulus. The trade-off is that there’s less redundancy in such a system — you can’t deduce the overall state from any individual value — which makes it easier for the system to get thrown off.
For the past couple of decades, research indicated that neural systems generally favored low-dimensional representations. Although the natural world contains an absolutely massive amount of information, the brain seemed to be discarding much of that in favor of simpler neural descriptions. But later analyses showed that this conclusion could be chalked up to weaknesses in the experiments themselves: The lab animals were presented with only a few stimuli, or very simple stimuli, and researchers could only record from a limited number of neurons at a time. “Of course those experiments gave those results,” said Kenneth Harris, a neuroscientist at University College London. “They couldn’t do anything different.”
So Harris and his colleagues revisited the problem, after creating a new technique for recording from 10,000 neurons simultaneously. As they showed mice nearly 3,000 images of natural scenes, they monitored the responses in the animals’ visual cortex and found a range of patterns that fit with a higher-dimensional picture of neural activity.
But the researchers also discovered something puzzling about that activity. The neurons didn’t care about all the dimensions equally: A few dimensions, or firing patterns, captured most of the neural responses to the visual stimuli. Adding other dimensions further increased that predictive power only by smaller and smaller increments. This decay followed what’s known as a power law, a special mathematical relationship “that’s been found almost everywhere people look for it,” said Jakob Macke, a computational neuroscientist at the Technical University of Munich who did not participate in the study.
Harris and his colleagues were stumped about what it might signify. Although recent studies have called the relevance (and even prevalence) of power laws into question — Harris quipped that even “the distribution of the number of exclamation marks in tweets from Donald Trump follows a power law” — there was something special about this one. It consistently had a particular slope, an exponent that couldn’t be explained by the mathematical structure of the stimuli.
“This sort of thing, this quantitative regularity in the data,” Harris said, “just doesn’t happen in biology. … We had absolutely no idea what it meant” — but it seemed to mean something.
In search of an explanation, they turned to previous mathematical work on the differentiability of functions. They found that if the power law mapping input to output decayed any slower, small changes in input would be able to generate large changes in output. The researchers referred to this as a breakdown in smoothness: The outputs produced by the underlying code were not always continuous.
It’s like being on the border of fractality, according to the co-leaders of the study, Carsen Stringer and Marius Pachitariu, both of whom worked in Harris’s lab and are now researchers at the Howard Hughes Medical Institute’s Janelia Research Campus in Virginia. “If you think of a fractal like the coastline of England,” Stringer said, “if you’re moving just a little bit along that coastline, you’re going to be changing very quickly, because there’s lots of jagged edges.”
In brain terms, that meant two very similar images could be represented by very different neural activity. “And that’s problematic,” she added. “If just one pixel changes, or if the image moves a bit, you don’t want your representation to totally change.”
Conversely, if the power law decayed any faster, the neural representations would become lower-dimensional. They would encode less information, emphasizing some key dimensions while ignoring the rest.
Taken together, those principles implied that the representations were as detailed and high-dimensional as they could get while still remaining smooth.
According to Harris, one way to interpret the finding is that with a slower decay, too much emphasis would be placed on less important dimensions (because if the curve relating neural activity to dimension were to get flatter, it would indicate that neural populations cared about all the dimensions more equally). Representations of the finer details in a stimulus would swamp the representation of the bigger features: The visual cortex would always be hypersensitive to certain trivial details, which would in turn make it difficult to formulate coherent perceptions and decisions. Meanwhile, with a faster decay, more weight than necessary would be placed on the larger features, overwhelming smaller features that might be relevant, too.
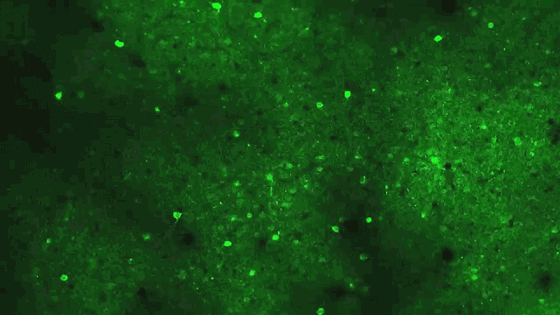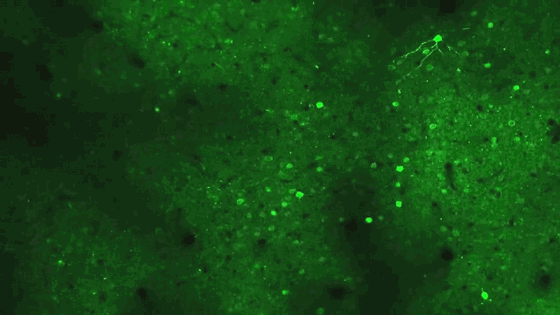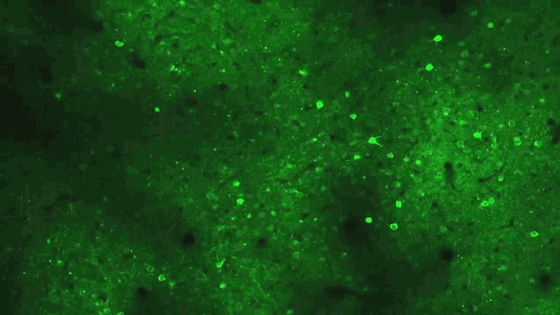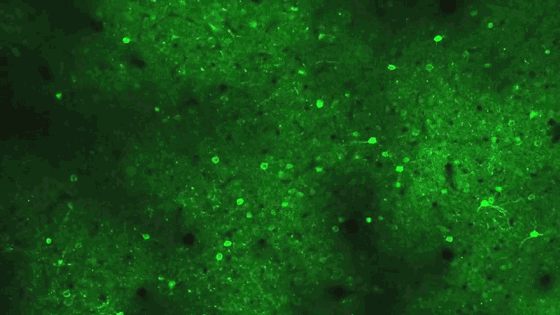
In this field of cells in the visual cortex of a laboratory mouse, the neurons light up as they fire in response to images presented by members of Harris’s team. The patterns of firing indicate that a power law is at work in the brain’s representation of the various images: Most neurons respond to the same stimuli; additional stimuli activate exponentially fewer cells.
Courtesy of Marius Pachitariu
The brain seems to get it just right. “This is in a cool sweet spot in between,” said Eric Shea-Brown, a mathematical neuroscientist at the University of Washington who was not involved in the study. “It’s a balance between being smooth and systematic, in terms of mapping like inputs to like responses, but other than that, expressing as much as possible about the input.”
Harris and his team performed another experiment to test their idea. The particular slope of the power law they found depended on incoming stimuli being high-dimensional, as any complex image is bound to be. But they calculated that if incoming visual inputs were simpler and lower-dimensional, the slope would have to be steeper to avoid a breakdown in smoothness.
That’s exactly what they saw when they analyzed the neural activity of mice presented with low-dimensional images.
The researchers now want to determine the biological mechanism that makes this power law possible. They also hope to continue probing the role it might play in other brain regions, in other tasks or behaviors, and in models of disease.
One tantalizing context that they’re starting to explore is artificial intelligence. Deep learning systems have their own problem with breakdowns in smoothness: After training, they might be able to accurately label an image as a panda, but changes made to just a handful of pixels — which would be practically invisible to the human eye — might lead them to classify the image as a chimpanzee instead. “It’s a pathological feature of these networks,” Harris said. “There are always going to be some details that they’re oversensitive to.”
Computer scientists have been trying to determine why this happens, and Harris thinks his team’s findings might offer some clues. Preliminary analyses of deep learning networks have revealed that some of their layers typically obey power laws that decay more slowly than those observed in the mouse experiments. Harris, Stringer and their colleagues suspect that these networks might be vulnerable because, unlike networks in the brain, they produce representations that aren’t totally continuous. Perhaps, Harris said, it might be possible to apply the lessons of the power law he’s been studying to deep learning networks to make them more stable. But this research is still in its early days, according to Macke, who is also studying power laws in deep learning networks.
Shea-Brown still thinks it’s a good place to start. “Continuous and smooth relationships,” he said, “seem obviously important for creating the ability to generalize and compare different types of situations in an environment.” Scientists are starting to understand how the brain uses its full network of neurons to encode representations of the world. Now, with “this surprising and beautiful result,” they have both “a new target … and a very useful reference point” in hand for thinking about that code.
Harris noted that the unexpected presence of this power law in the visual cortex “was just something that came out in the data.” Now that other research questions can be pursued using his group’s technique for imaging and analyzing thousands of neurons at once, “this thing with the power law will probably be some very basic first finding,” with many other unanticipated insights on the horizon. “This whole approach is going to completely change the way we think about things.”
Editor’s note: Kenneth Harris receives funding from the Simons Foundation, which also funds this editorially independent magazine.