How to Assess Risks During the Coronavirus Pandemic

James Round for Quanta Magazine
Introduction
Our August Insights puzzle challenged you to make sense of the daily torrent of COVID-19 data as an exercise in personal risk management.
Our first puzzle required judging the reliability and proper application of the key statistics that we are all familiar with: confirmed cases, reported deaths and testing numbers. What makes this hard is that it requires reasoning in the face of uncertainty, and even sophisticated modeling groups don’t agree completely. Nevertheless, it’s a great exercise for clarifying one’s concepts.
In general, there are several tested methods in science for making headway in these kinds of situations:
1. Try to establish which measurements are likely to be the most reliable;
2. Correct for sources of error if possible;
3. Use any data that is known to be accurate to establish upper and lower bounds; or
4. Triangulate by using different independent methods to reach a solution, and then compare them and take a median value as the best estimate. If astronomers can use this to estimate how fast the universe is expanding, we can use it to figure out how fast COVID is spreading!
Let’s see how we can apply these techniques.
Puzzle 1: Threading the Needle
Our first puzzle is simple to state: Is the actual number of people infected per day by the novel coronavirus in the U.S. during this current period (late July to early August) greater, less than or about equal to the number in the initial peak in the middle of April 2020? If it’s higher or lower, to what extent? (Use sources that are recognized as reliable, such as Johns Hopkins University, The New York Times, Oxford University or the CDC.)
Note that the peak of newly confirmed cases as shown by the seven-day average in the second week of April was around 31,000 every day, while the number during the past week is about twice that — around 60,000. On the other hand, the peak number of reported deaths by COVID-19 per day based on the seven-day moving average was over 2,200 in mid-April, but it’s about half that — around 1,200 — in early August. There is no evidence that the lethality of the virus itself has changed, so this disparity must have other explanations.
Let’s look at the reliability of our measures first. The two statistics presented here, the number of confirmed cases and the number of reported deaths, are not equally reliable or useful. The former is completely unreliable, as I mentioned in the puzzle description itself and elaborated in a comment. The number of confirmed COVID cases is meaningless for comparing two different areas or two different times as we are doing here. That’s because this measure depends on the amount and quality of testing. What we want is the number of people truly infected at both times and not merely the number of confirmed cases, which is much, much smaller. Finding out the true infection rate requires a well-designed program of random population testing, which we don’t have. The actual testing performed in the U.S. has been haphazard — it would have required a superhuman amount of that kind of testing to come close to measuring the infection rate, especially in a pandemic that has spread so fast.
At the time of the initial peak in April, only the very sick were tested in the U.S. Mild or asymptomatic cases were not detected at all. When the second peak arrived in midsummer, after testing capacity was ramped up over three months, we had 20 times as much testing per capita as before. At least in theory, tests were available to people with mild symptoms on demand, or for screening (often a requirement for going to college or before a medical procedure), which meant many mild and asymptomatic cases were detected. As I mentioned in the puzzle, the ratio of the number of tests to the total number of confirmed cases for the entire U.S. was only about 5-to-1 in mid-April, but it was about 12.5-to-1 in early August.
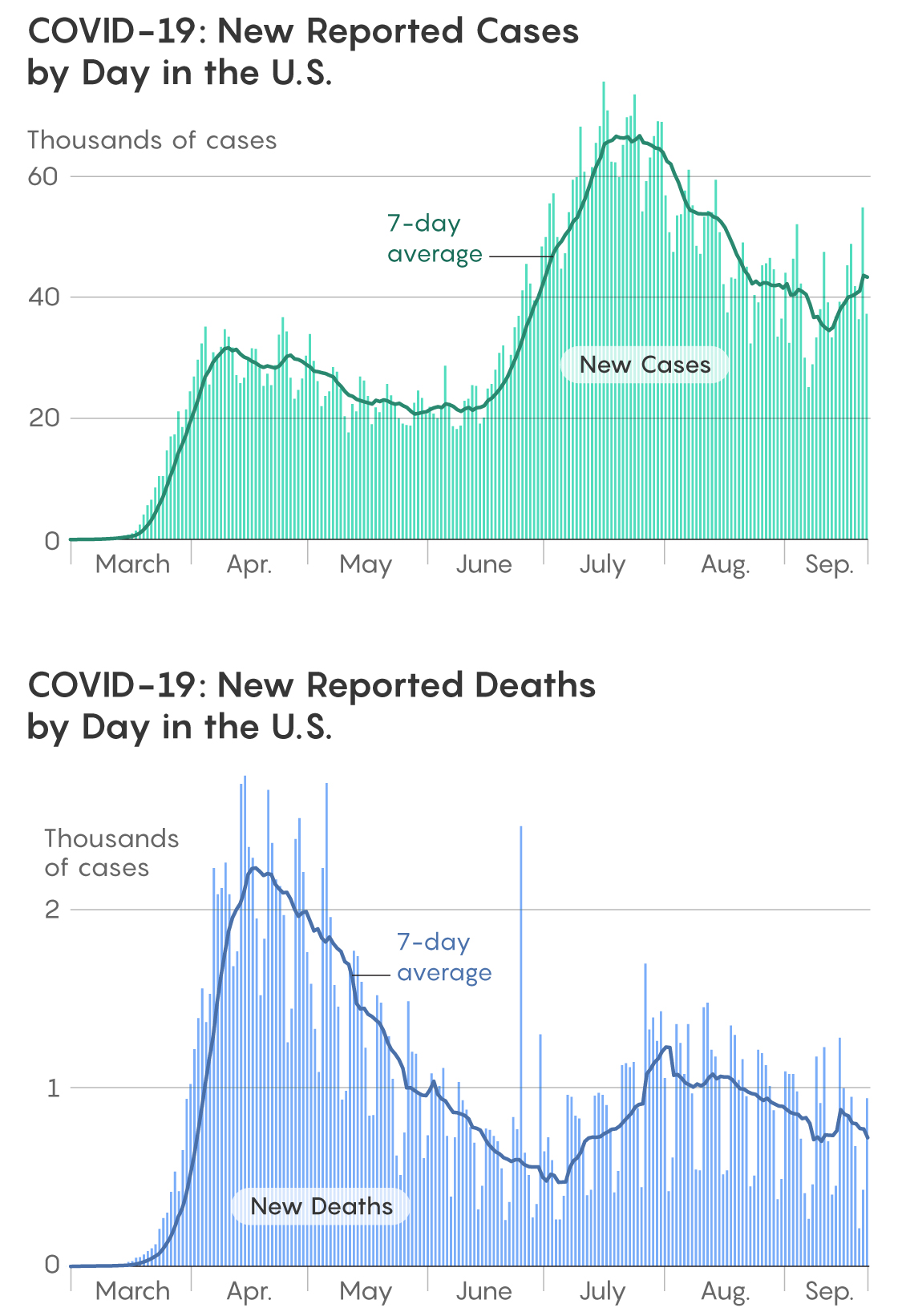
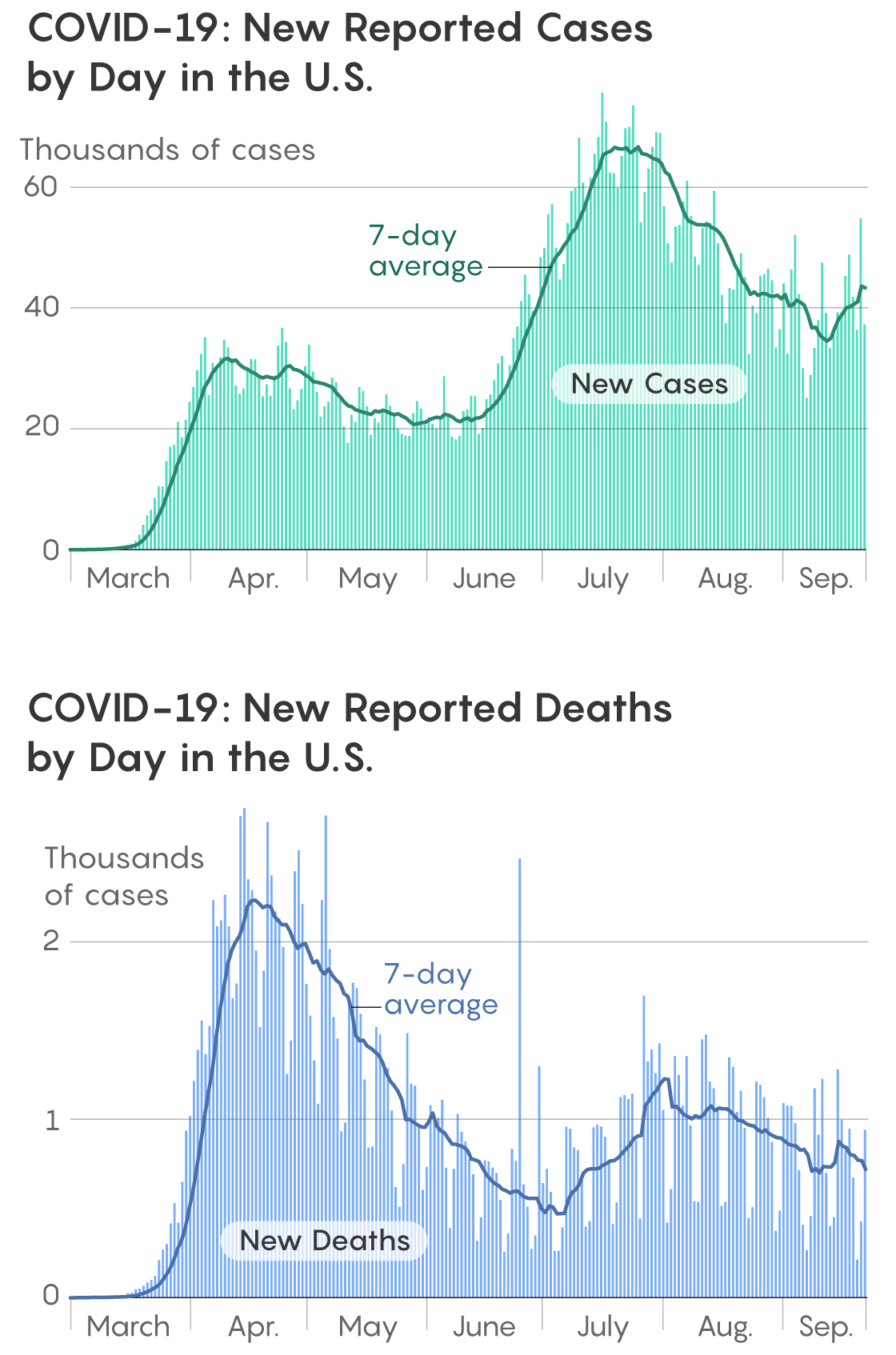
Samuel Velasco/Quanta Magazine; Source: The New York Times
The number of actual novel coronavirus infections was far higher than the number of confirmed cases in March and April. The number of actual cases has been estimated by the CDC, based on antibody tests, to have been about 10 times higher than the number of reported cases in the U.S. in that period (this ratio varied between 6 and 24 times the number of reported cases in different states).
If the number of confirmed cases so grossly underestimates the actual statistic it is trying to measure, what use is it? Generally, it is only useful for detecting trends in novel coronavirus infection in a single place, during a small enough time window that the amount of testing doesn’t vary much. It is useless for comparing the actual number of infections at two different times when the amount of testing has changed.
What about the number of reported deaths? This, too, is not completely accurate. Our best data indicates that the number of U.S. deaths has been undercounted by about 30%, mainly because it’s hard to accurately attribute deaths to COVID-19, especially when people die outside of hospitals. But attribution criteria usually do not change drastically, so the number of deaths at our two different peaks can be reasonably compared. (Comparisons between countries are more problematic but still possible between countries with good health care reporting: The numbers may be off by tens of percentage points, but not by an order of magnitude as the confirmed case numbers are.)
Absolute testing numbers are of course accurate since they come from what we do, and not from the virus. However, testing varies greatly from place to place, and crucially important details such as the time, purpose and context of a test are not available. This reduces their utility.
So it would be OK to use the number of reported deaths or the number of tests,to carry out our calculation. We should avoid using confirmed case numbers.
Adrien took a good stab at this. Using a combination of testing numbers and the death percentage in seniors, he made an extremely conservative assumption that only seniors were tested back in April. He obtained a lower bound of 0.65 for the ratio of first-peak infections to second-peak infections and an upper bound of 1.83. This leaves both possibilities open: There could have been more COVID infections in the spring peak compared to the summer one, or fewer. The midpoint ratio is 1.24, meaning that there were probably slightly more infections in the first peak rather than the second.
This was a good attempt, but the range is too broad. Let’s see if we can narrow it down.
To do so, we can use the fact that the virus has not become more or less virulent over the course of the pandemic. Its average lethality — also known as the infection fatality rate (IFR) — has remained much the same over this time, absent any change in human interventions. The IFR is a simple ratio:
IFR = $latex \frac{Number\, of\, Deaths}{Number\, of\, Infections}$
If the IFR is constant, then the number of infections is proportional to the number of deaths. So we can put:
$latex \frac{Number\, of\, Infections_1}{Number\, of\, Infections_2}$ = $latex \frac{Number\, of\, Deaths_1}{Number\, of\, Deaths_2}$
The left-hand side is the ratio we want — if it is greater than 1, there were more infections in the first peak. If the IFR remained the same, then the answer is clear: It’s the ratio of the reported deaths, which is 2,200/1,200, or 1.83. But of course it’s not that simple. With improved interventions after the first peak, we may have avoided some deaths that might have taken place otherwise. We might have lowered the average IFR.
I mentioned two ways we could have done this. The first concerns age. The COVID IFR varies a great deal depending on age. In our June puzzle, I included a table of CDC data showing a breakdown of about 70,000 U.S. COVID deaths by age range. Here is a similar one that shows the age breakdown of about 176,000 deaths as of September 5.
| Age Range | Number of U.S. COVID Deaths |
Percentage |
| Under 1 year | 19 | 0.01% |
| 1-4 years | 14 | 0.01% |
| 5-14 years | 29 | 0.02% |
| 15-24 years | 315 | 0.18% |
| 25-34 years | 1,360 | 0.77% |
| 35-44 years | 3,542 | 2% |
| 45-54 years | 9,324 | 5% |
| 55-64 years | 22,254 | 13% |
| 65-74 years | 37,684 | 21% |
| 75-84 years | 46,487 | 26% |
| 85 years and over |
54,838 | 31% |
| Total | 175,866 | 100% |
As you can see, the IFR rises dramatically with increasing age. (This is why countries with younger populations have a lower average COVID IFR and those with older populations have a higher one. At the start of the pandemic, the IFR worldwide was between 0.5% and 1%, and a meta-analysis — medicine’s magical triangulating mechanism — pegged the mean number at 0.68%.)
One way we might have lowered the average IFR is by getting better at protecting people in nursing homes and other institutions for the elderly. I expected this to be true, but it turns out that the percentages of deaths in all these age ranges are almost exactly the same now as they were at the time of the previous peak. They are within a single percentage point in every age range — almost uncannily consistent! This indicates that the age distribution of the infection remained pretty much the same at the time of the two peaks and there has been no discernible change in IFR on account of shielding older people.
The other intervention that could have changed the average IFR is an improvement in treatment. This has certainly happened. Steroids were shown by the British RECOVERY clinical trial to significantly decrease the mortality of COVID patients on respirators or on oxygen. The simple practice of “proning” — turning patients onto their stomachs for prolonged periods in ICUs — was shown to improve oxygenation. And finally, some antiviral agents, anticoagulants and anti-inflammatory drugs have been found to provide some benefit. All these treatments are part of U.S. hospital ICU protocols today, which was not the case back in April. And they have saved lives. But how do we determine how many?
Fortunately, there’s a study available that performed a comprehensive meta-analysis (another ready-made triangulation we can use) of a large number of published studies on this issue. It concludes that whereas 60% of ICU patients died at the previous peak, advances in care have brought the number down to 40%. That is, if we saw a certain proportion of patients die at the time of the second peak, we likely would have seen 50% more die during the first peak. Of course, these improvements in treatment do not affect those who died before they could be admitted into hospitals. According to CDC data, such deaths constitute about a third of all COVID deaths. If we take this factor into consideration, the number of deaths that were prevented at the time of the second peak comes out to be one-third of the observed deaths rather than one-half. (Strictly speaking, I should have analyzed all the ICU studies and come up with confidence intervals around this estimate, but we’ll leave that to the professionals.)
So instead of the 1,200 peak daily deaths we saw in the summer peak we would have seen about 400 more — a total of approximately 1,600 daily deaths during the second peak. The fact that a quarter of the deaths that would have otherwise taken place were avoided, implies that by improving the practice of medicine, we have reduced the average COVID IFR from our assumed initial value, 0.68, to 0.51. By this model, the actual infections were about 325,000, or about 10 times the first confirmed case peak, and about 235,000, or about 3.5 times the second. Interestingly, these factors, 10 and 3.5, are pretty close to the reverse of the tests per confirmed case numbers at these two points in time. By this calculation, the ratio of infections in the first peak to that in the second was 1.38.
What this means is that by practicing better medicine we have saved about 30,000 lives in the U.S. this summer. We will continue to save many more lives this way, offsetting some of the tragic human loss that could have been prevented if we had followed the best pandemic control practices as some other countries have.
Puzzle 2: Establishing a Risk Baseline
Imagine that you live in a state with a population of 1 million that had 1,000 deaths due to COVID-19 over a period of 100 days during this pandemic. Your habits and behavior during this period lead you to believe that your risk is average. What was your average daily risk in micromorts?
This hypothetical state is very similar to Rhode Island, which has a population of 1.06 million and had about 970 COVID deaths in the 100 days starting April 1.
If your risk is average, it is tempting to just take the total risk, which is 1,000 micromorts (imagine having three colonoscopies in three months), and divide by 100 to get 10 micromorts per day. Because these fractions are small, this approximation works. Mortality risk numbers are generally very low, so you can pull off this trick. But probabilities of independent events have to be multiplied, not added, so it’s important to be able to know the right way to do it when required.
The correct way to do this is to first determine your probability of surviving the hundred days, which is 1 − 1/1,000 = 999/1,000. Now you have to find a fraction which, when raised to the 100th power, gives 0.999. Take the log of 0.999 and divide it by 100. You now have the log of the hundredth root of 0.999. Raise 10 to that power and you have your probability of surviving one day (0.999989995). Now subtract this result from 1, which gives the probability of dying on a given day, and multiply the result by 1 million to get 10.005, which is your risk in micromorts. This risk is like skydiving an average of one-and-a-half times every day. Most of the time, you’ll be fine, but the risk will add up after 1,000 dives. That’s the risk you took by merely living through the pandemic in its initial surge!
Puzzle 3: How Safe Is Your Backyard Party?
Let’s say the numbers in your state are such that 1 in 500 people tested at random are positive for COVID-19 (this is the active infection rate). You go to a backyard party with 20 other guests. You interact closely with five people, moderately with another five and distantly with the remaining 10. The interactions are such that your chance of catching the virus from any person in the first group is 1 in 10 if that person is infected; for the second group the chance of infection is 1 in 30, and for the third group it’s 1 in 50. What’s your risk of infection? How many micromorts does that translate to?
This problem is a straight probability calculation. The steps are best shown in the following tables, which can be translated to a spreadsheet. The first table shows the steps needed to calculate the risk of being infected by each group.
| Close group (risk: 1/10) |
Moderate group (1/30) |
Distant group (1/50) |
|
| p (infected) |
1/500 | 1/500 | 1/500 |
| p (this person infects you) |
1/500 × 1/10 = 0.0002 |
1/15,000 | 1/25,000 |
| p (this person doesn’t infect you) |
1 − 0.0002 = 0.9998 | 0.99993 | 0.99996 |
| number in group | 5 | 5 | 10 |
| p (no one in group infects you) |
0.99985 = 0.99900 |
0.99967 | 0.99960 |
Start with the close group (1/10). This column calculates the probability of getting infected by this group: 1/10 is the probability of transmission from each person. Now imagine you interact with a person in this group. The next cell shows the probability of an individual in this group being infected (1/500), which is true of everyone you meet. Next is your probability of getting infected by this person (1/500 × 1/10). Next is the probability of not being infected by this person (1 − the previous result, giving 0.9998). Next you have to do the same with all five individuals in the group. Raise the previous number to the fifth power. This gives the chance of not being infected by anyone in this group. The next two columns do the same calculations for the other two groups.
The second table shows the risk of being infected by any of the three groups, and the risk of death.
| p (no one in any group infects you) |
Product of all groups in table 1 = 0.99827 |
| p (someone infects you) |
1 − previous product = 0.00173 |
| p (your risk of dying) |
previous result × 0.0051 = 0.00000878 |
| micromorts | previous result × 1,000,000 = 8.8 |
The first cell multiplies all three probabilities: That’s the chance of not being infected by any of the three groups. Next, subtract this from 1. This gives the probability of getting infected. The third cell gives the chance of dying (assuming the 0.51% IFR we calculated above): Multiply by 0.0051. Finally, convert this into micromorts by multiplying by 1 million. The answer is 8.8 micromorts, which means the party effectively puts you at an additional risk almost equal to that of dying on a given day at the height of the pandemic — or a little more than skydiving once. Notice how converting to micromorts expresses the risk in an emotionally intelligible way. Also notice how the extremely small risks in each encounter build up to create a non-negligible risk. That’s why larger groups pose greater risks, and why it’s a good idea to limit group sizes during pandemics.
The risk we calculated above is the kind of risk that a moderately uninhibited, non-socially distanced party would have. Most well-distanced parties would carry lower risks, which would be further decreased by masking whenever possible. The multiplicative mathematics of mask wearing is truly amazing: Masks are much more effective than you think, even when they are not worn universally. Check out this excellent explanation and the entertaining video it links to.
Puzzle 4: The Superspreader Factor
Assume that your average risk of infection at a single backyard party is what you calculated in Puzzle 3. However, factor in that 10% of parties account for 80% of infections. How does that affect your risk of infection from attending one backyard party? What is the risk of catching an infection if you are at a party attended by an infected person? (Note that the chances of catching an infection from specific groups in the party, given in Puzzle 3, are no longer relevant for this problem.)
The first one is a trick question. Your risk of infection from attending one backyard party remains the same as always! Superspreaders concentrate the risk in 1 out of 10 parties, but the risk at that one party is far greater. Your other nine parties become very low-risk affairs, and it all evens out because you cannot tell beforehand whether the one party you attend is a superspreader party or not.
To calculate it explicitly: Suppose your previous equal-risk parties had an individual risk of 0.05 (1 in 20) chance of infection. Then on average one person would be infected at every party, so 10 parties would cause 10 infections. In the superspreader scenario, one party would cause eight infections (8/20 chance of infection per person), and the other nine parties would share two infections (2/180 chance per person). So your probability of infection is (1/10 × 8/20) + (9/10 × 2/180), which simplifies to 8/200 + 2/200 = 1/20, which is the same as before. This can be easily proved algebraically, but I’ll leave that to you.
For the second question, I’ll simplify and assume that no party has more than one infected person. In that case, if you are at a party with an infected person, you have a 1/3 chance of being at the superspreader event where you have an 8/20 chance of being infected, and a 2/3 chance of being in a non-superspreader event where your chance of being infected is 1/20. The expression to be calculated is (1/3 × 8/20) + (2/3 × 1/20), which simplifies to 8/60 + 2/60 = 10/60, or 0.167. This is over three times the risk you would have in the non-superspreader scenario. And as Adrien said, if you were the host of such a party, would you like to be responsible for having infected eight others and many more downstream?
I hope these calculations have given you a feel for how risk builds up. The best way to socialize safely is to diminish the three D’s — density, duration and diversity — and additionally, to wear a mask whenever possible.
Thanks to all who commented. The prize for this month goes to Adrien, our “best man” for this month, for his long, amusing and very personal comment. Congratulations, and I hope you get to be the real best man sometime soon. In the meantime, enjoy the prize!
Take care, everyone, and practice safe and responsible socializing.



