New AI Strategy Mimics How Brains Learn to Smell
Shayla Fish for Quanta Magazine
Introduction
Today’s artificial intelligence systems, including the artificial neural networks broadly inspired by the neurons and connections of the nervous system, perform wonderfully at tasks with known constraints. They also tend to require a lot of computational power and vast quantities of training data. That all serves to make them great at playing chess or Go, at detecting if there’s a car in an image, at differentiating between depictions of cats and dogs. “But they are rather pathetic at composing music or writing short stories,” said Konrad Kording, a computational neuroscientist at the University of Pennsylvania. “They have great trouble reasoning meaningfully in the world.”
To overcome those limitations, some research groups are turning back to the brain for fresh ideas. But a handful of them are choosing what may at first seem like an unlikely starting point: the sense of smell, or olfaction. Scientists trying to gain a better understanding of how organisms process chemical information have uncovered coding strategies that seem especially relevant to problems in AI. Moreover, olfactory circuits bear striking similarities to more complex brain regions that have been of interest in the quest to build better machines.
Computer scientists are now beginning to probe those findings in machine learning contexts.
Flukes and Revolutions
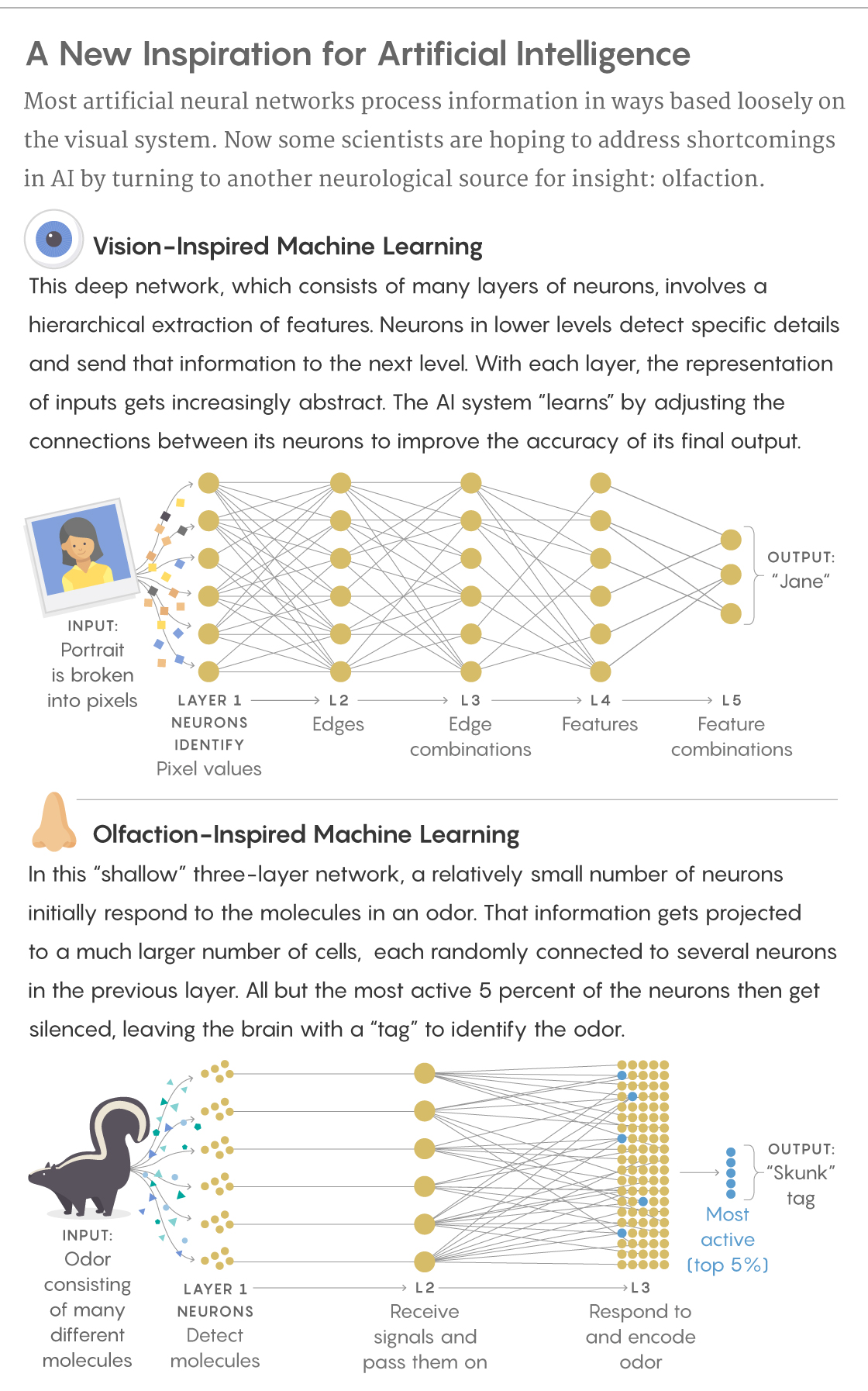
State-of-the-art machine learning techniques used today were built at least in part to mimic the structure of the visual system, which is based on the hierarchical extraction of information. When the visual cortex receives sensory data, it first picks out small, well-defined features: edges, textures, colors, which involves spatial mapping. The neuroscientists David Hubel and Torsten Wiesel discovered in the 1950s and ’60s that specific neurons in the visual system correspond to the equivalent of specific pixel locations in the retina, a finding for which they won a Nobel Prize.
As visual information gets passed along through layers of cortical neurons, details about edges and textures and colors come together to form increasingly abstract representations of the input: that the object is a human face, and that the identity of the face is Jane, for example. Every layer in the network helps the organism achieve that goal.
Deep neural networks were built to work in a similarly hierarchical way, leading to a revolution in machine learning and AI research. To teach these nets to recognize objects like faces, they are fed thousands of sample images. The system strengthens or weakens the connections between its artificial neurons to more accurately determine that a given collection of pixels forms the more abstract pattern of a face. With enough samples, it can recognize faces in new images and in contexts it hasn’t seen before.
Researchers have had great success with these networks, not just in image classification but also in speech recognition, language translation and other machine learning applications. Still, “I like to think of deep nets as freight trains,” said Charles Delahunt, a researcher at the Computational Neuroscience Center at the University of Washington. “They’re very powerful, so long as you’ve got reasonably flat ground, where you can lay down tracks and have a huge infrastructure. But we know biological systems don’t need all that — that they can handle difficult problems that deep nets can’t right now.”
Take a hot topic in AI: self-driving cars. As a car navigates a new environment in real time — an environment that’s constantly changing, that’s full of noise and ambiguity — deep learning techniques inspired by the visual system might fall short. Perhaps methods based loosely on vision, then, aren’t the right way to go. That vision was such a dominant source of insight at all was partly incidental, “a historical fluke,” said Adam Marblestone, a biophysicist at the Massachusetts Institute of Technology. It was the system that scientists understood best, with clear applications to image-based machine learning tasks.
But “every type of stimulus doesn’t get processed in the same way,” said Saket Navlakha, a computer scientist at the Salk Institute for Biological Studies in California. “Vision and olfaction are very different types of signals, for example. … So there may be different strategies to deal with different types of data. I think there could be a lot more lessons beyond studying how the visual system works.”
He and others are beginning to show that the olfactory circuits of insects may hold some of those lessons. Olfaction research didn’t take off until the 1990s, when the biologists Linda Buck and Richard Axel, both at Columbia University at the time, discovered the genes for odor receptors. Since then, however, the olfactory system has become particularly well characterized, and it’s something that can be studied easily in flies and other insects. It’s tractable in a way that visual systems are not for studying general computational challenges, some scientists argue.
“We work on olfaction because it’s a finite system that you can characterize relatively completely,” Delahunt said. “You’ve got a fighting chance.”
“People can already do such fantastic stuff with vision,” added Michael Schmuker, a computational neuroscientist at the University of Hertfordshire in England. “Maybe we can do fantastic stuff with olfaction, too.”
Random and Sparse Networks
Olfaction differs from vision on many fronts. Smells are unstructured. They don’t have edges; they’re not objects that can be grouped in space. They’re mixtures of varying compositions and concentrations, and they’re difficult to categorize as similar to or different from one another. It’s therefore not always clear which features should get attention.
These odors are analyzed by a shallow, three-layer network that’s considerably less complex than the visual cortex. Neurons in olfactory areas randomly sample the entire receptor space, not specific regions in a hierarchy. They employ what Charles Stevens, a neurobiologist at the Salk Institute, calls an “antimap.” In a mapped system like the visual cortex, the position of a neuron reveals something about the type of information it carries. But in the antimap of the olfactory cortex, that’s not the case. Instead, information is distributed throughout the system, and reading that data involves sampling from some minimum number of neurons. An antimap is achieved through what’s known as a sparse representation of information in a higher dimensional space.
Take the olfactory circuit of the fruit fly: 50 projection neurons receive input from receptors that are each sensitive to different molecules. A single odor will excite many different neurons, and each neuron represents a variety of odors. It’s a mess of information, of overlapped representations, that is at this point represented in a 50-dimensional space. The information is then randomly projected to 2,000 so-called Kenyon cells, which encode particular scents. (In mammals, cells in what’s known as the piriform cortex handle this.) That constitutes a 40-fold expansion in dimension, which makes it easier to distinguish odors by the patterns of neural responses.
Lucy Reading-Ikkanda/Quanta Magazine
“Let’s say you have 1,000 people and you stuff them into a room and try to organize them by hobby,” Navlakha said. “Sure, in this crowded space, you might be able to find some way to structure these people into their groups. But now, say you spread them out on a football field. You have all this extra space to play around with and structure your data.”
Once the fly’s olfactory circuit has done that, it needs to figure out a way to identify distinct odors with non-overlapping neurons. It does this by “sparsifying” the data. Only around 100 of the 2,000 Kenyon cells — 5 percent — are highly active in response to given smells (less active cells are silenced), providing each with a unique tag.
In short, while traditional deep networks (again taking their cues from the visual system) constantly change the strength of their connections as they “learn,” the olfactory system generally does not seem to train itself by adjusting the connections between its projection neurons and Kenyon cells.
As researchers studied olfaction in the early 2000s, they developed algorithms to determine how random embedding and sparsity in higher dimensions helped computational efficiency. One pair of scientists, Thomas Nowotny of the University of Sussex in England and Ramón Huerta of the University of California, San Diego, even drew connections to another type of machine learning model, called a support vector machine. They argued that the ways both the natural and artificial systems processed information, using random organization and dimensionality expansion to represent complex data efficiently, were formally equivalent. AI and evolution had converged, independently, on the same solution.
Intrigued by that connection, Nowotny and his colleagues continue to explore the interface between olfaction and machine learning, looking for a deeper link between the two. In 2009, they showed that an olfactory model based on insects, initially created to recognize odors, could also recognize handwritten digits. Moreover, removing the majority of its neurons — to mimic how brain cells die and aren’t replaced — did not affect its performance too much. “Parts of the system might go down, but the system as a whole would keep working,” Nowotny said. He foresees implementing that type of hardware in something like a Mars rover, which has to operate under harsh conditions.
But for a while, not much work was done to follow up on those findings — that is until very recently, when some scientists began revisiting the biological structure of olfaction for insights into how to improve more specific machine learning problems.
Hard-Wired Knowledge and Fast Learning
Delahunt and his colleagues have repeated the same kind of experiment Nowotny conducted, using the moth olfactory system as a foundation and comparing it to traditional machine learning models. Given fewer than 20 samples, the moth-based model recognized handwritten digits better, but when provided with more training data, the other models proved much stronger and more accurate. “Machine learning methods are good at giving very precise classifiers, given tons of data, whereas the insect model is very good at doing a rough classification very rapidly,” Delahunt said.
Olfaction seems to work better when it comes to speed of learning because, in that case, “learning” is no longer about seeking out features and representations that are optimal for the particular task at hand. Instead, it’s reduced to recognizing which of a slew of random features are useful and which are not. “If you can train with just one click, that would be much more beautiful, right?” said Fei Peng, a biologist at Southern Medical University in China.
In effect, the olfaction strategy is almost like baking some basic, primitive concepts into the model, much like a general understanding of the world is seemingly hard-wired into our brains. The structure itself is then capable of some simple, innate tasks without instruction.
One of the most striking examples of this came out of Navlakha’s lab last year. He, along with Stevens and Sanjoy Dasgupta, a computer scientist at the University of California, San Diego, wanted to find an olfaction-inspired way to perform searches on the basis of similarity. Just as YouTube can generate a sidebar list of videos for users based on what they’re currently watching, organisms must be able to make quick, accurate comparisons when identifying odors. A fly might learn early on that it should approach the smell of a ripe banana and avoid the smell of vinegar, but its environment is complex and full of noise — it’s never going to experience the exact same odor again. When it detects a new smell, then, the fly needs to figure out which previously experienced odors the scent most resembles, so that it can recall the appropriate behavioral response to apply.
Navlakha created an olfactory-based similarity search algorithm and applied it to data sets of images. He and his team found that their algorithm performed better than, and sometimes two to three times as well as, traditional nonbiological methods involving dimensionality reduction alone. (In these more standard techniques, objects were compared by focusing on a few basic features, or dimensions.) The fly-based approach also “used about an order of magnitude less computation to get similar levels of accuracy,” Navlakha said. “So it either won in cost or in performance.”
Nowotny, Navlakha and Delahunt showed that an essentially untrained network could already be useful for classification computations and similar tasks. Building in such an encoding scheme leaves the system poised to make subsequent learning easier. It could be used in tasks that involve navigation or memory, for instance — situations in which changing conditions (say, obstructed paths) might not leave the system with much time to learn or many examples to learn from.
Peng and his colleagues have started research on just that, creating an ant olfactory model to make decisions about how to navigate a familiar route from a series of overlapped images.
In work currently under review, Navlakha has applied a similar olfaction-based method for novelty detection, the recognition of something as new even after having been exposed to thousands of similar objects in the past.
And Nowotny is examining how the olfactory system processes mixtures. He’s already seeing possibilities for applications to other machine learning challenges. For instance, organisms perceive some odors as a single scent and others as a mix: A person might take in dozens of chemicals and know she’s smelled a rose, or she might sense the same number of chemicals from a nearby bakery and differentiate between coffee and croissants. Nowotny and his team have found that separable odors aren’t perceived at the same time; rather, the coffee and croissant odors are processed very rapidly in alternation.
That insight could be useful for artificial intelligence, too. The cocktail party problem, for example, refers to how difficult it is to separate numerous conversations in a noisy setting. Given several speakers in a room, an AI might solve this problem by cutting the sound signals into very small time windows. If the system recognized sound coming from one speaker, it could try to suppress inputs from the others. By alternating like that, the network could disentangle the conversations.
Enter the Insect Cyborgs
In a paper posted last month on the scientific preprint site arxiv.org, Delahunt and his University of Washington colleague J. Nathan Kutz took this kind of research one step further by creating what they call “insect cyborgs.” They used the outputs of their moth-based model as the inputs of a machine learning algorithm, and saw improvements in the system’s ability to classify images. “It gives the machine learning algorithm much stronger material to work with,” Delahunt said. “Some different kind of structure is being pulled out by the moth brain, and having that different kind of structure helps the machine learning algorithm.”
Some researchers now hope to also use studies in olfaction to figure out how multiple forms of learning can be coordinated in deeper networks. “But right now, we’ve covered only a little bit of that,” Peng said. “I’m not quite sure how to improve deep learning systems at the moment.”
One place to start could lie not only in implementing olfaction-based architecture but also in figuring out how to define the system’s inputs. In a paper just published in Science Advances, a team led by Tatyana Sharpee of the Salk Institute sought a way to describe smells. Images are more or less similar depending on the distances between their pixels in a kind of “visual space.” But that kind of distance doesn’t apply to olfaction. Nor can structural correlations provide a reliable bearing: Odors with similar chemical structures can be perceived as very different, and odors with very different chemical structures can be perceived as similar.
Sharpee and her colleagues instead defined odor molecules in terms of how often they’re found together in nature (for the purposes of their study, they examined how frequently molecules co-occurred in samples of various fruits and other substances). They then created a map by placing odor molecules closer together if they tended to co-activate, and farther apart if they did so more rarely. They found that just as cities map onto a sphere (the Earth), the odor molecules map onto a hyperbolic space, a sphere with negative curvature that looks like a saddle.
Sharpee speculated that feeding inputs with hyperbolic structure into machine learning algorithms could help with the classification of less-structured objects. “There’s a starting assumption in deep learning that the inputs should be done in a Euclidean metric,” she said. “I would argue that one could try changing that metric to a hyperbolic one.” Perhaps such a structure could further optimize deep learning systems.
A Common Denominator
Right now, much of this remains theoretical. The work by Navlakha and Delahunt needs to be scaled up to much more difficult machine learning problems to determine whether olfaction-inspired models stand to make a difference. “This is all still emerging, I think,” Nowotny said. “We’ll see how far it will go.”
What gives researchers hope is the striking resemblance the olfactory system’s structure bears to other regions of the brain across many species, particularly the hippocampus, which is implicated in memory and navigation, and the cerebellum, which is responsible for motor control. Olfaction is an ancient system dating back to chemosensation in bacteria, and is used in some form by all organisms to explore their environments.
“It seems to be closer to the evolutionary origin point of all the things we’d call cortex in general,” Marblestone said. Olfaction might provide a common denominator for learning. “The system gives us a really conserved architecture, one that’s used for a variety of things across a variety of organisms,” said Ashok Litwin-Kumar, a neuroscientist at Columbia. “There must be something fundamental there that’s good for learning.”
The olfactory circuit could act as a gateway to understanding the more complicated learning algorithms and computations used by the hippocampus and cerebellum — and to figuring out how to apply such insights to AI. Researchers have already begun turning to cognitive processes like attention and various forms of memory, in hopes that they might offer ways to improve current machine learning architectures and mechanisms. But olfaction might offer a simpler way to start forging those connections. “It’s an interesting nexus point,” Marblestone said. “An entry point into thinking about next-generation neural nets.”