An Idea From Physics Helps AI See in Higher Dimensions

The new deep learning techniques, which have shown promise in identifying lung tumors in CT scans more accurately than before, could someday lead to better medical diagnostics.
Olena Shmahalo/Quanta Magazine
Introduction
Computers can now drive cars, beat world champions at board games like chess and Go, and even write prose. The revolution in artificial intelligence stems in large part from the power of one particular kind of artificial neural network, whose design is inspired by the connected layers of neurons in the mammalian visual cortex. These “convolutional neural networks” (CNNs) have proved surprisingly adept at learning patterns in two-dimensional data — especially in computer vision tasks like recognizing handwritten words and objects in digital images.
But when applied to data sets without a built-in planar geometry — say, models of irregular shapes used in 3D computer animation, or the point clouds generated by self-driving cars to map their surroundings — this powerful machine learning architecture doesn’t work well. Around 2016, a new discipline called geometric deep learning emerged with the goal of lifting CNNs out of flatland.
Now, researchers have delivered, with a new theoretical framework for building neural networks that can learn patterns on any kind of geometric surface. These “gauge-equivariant convolutional neural networks,” or gauge CNNs, developed at the University of Amsterdam and Qualcomm AI Research by Taco Cohen, Maurice Weiler, Berkay Kicanaoglu and Max Welling, can detect patterns not only in 2D arrays of pixels, but also on spheres and asymmetrically curved objects. “This framework is a fairly definitive answer to this problem of deep learning on curved surfaces,” Welling said.
Already, gauge CNNs have greatly outperformed their predecessors in learning patterns in simulated global climate data, which is naturally mapped onto a sphere. The algorithms may also prove useful for improving the vision of drones and autonomous vehicles that see objects in 3D, and for detecting patterns in data gathered from the irregularly curved surfaces of hearts, brains or other organs.
The researchers’ solution to getting deep learning to work beyond flatland also has deep connections to physics. Physical theories that describe the world, like Albert Einstein’s general theory of relativity and the Standard Model of particle physics, exhibit a property called “gauge equivariance.” This means that quantities in the world and their relationships don’t depend on arbitrary frames of reference (or “gauges”); they remain consistent whether an observer is moving or standing still, and no matter how far apart the numbers are on a ruler. Measurements made in those different gauges must be convertible into each other in a way that preserves the underlying relationships between things.
For example, imagine measuring the length of a football field in yards, then measuring it again in meters. The numbers will change, but in a predictable way. Similarly, two photographers taking a picture of an object from two different vantage points will produce different images, but those images can be related to each other. Gauge equivariance ensures that physicists’ models of reality stay consistent, regardless of their perspective or units of measurement. And gauge CNNs make the same assumption about data.
“The same idea [from physics] that there’s no special orientation — they wanted to get that into neural networks,” said Kyle Cranmer, a physicist at New York University who applies machine learning to particle physics data. “And they figured out how to do it.”
Escaping Flatland
Michael Bronstein, a computer scientist at Imperial College London, coined the term “geometric deep learning” in 2015 to describe nascent efforts to get off flatland and design neural networks that could learn patterns in nonplanar data. The term — and the research effort — soon caught on.
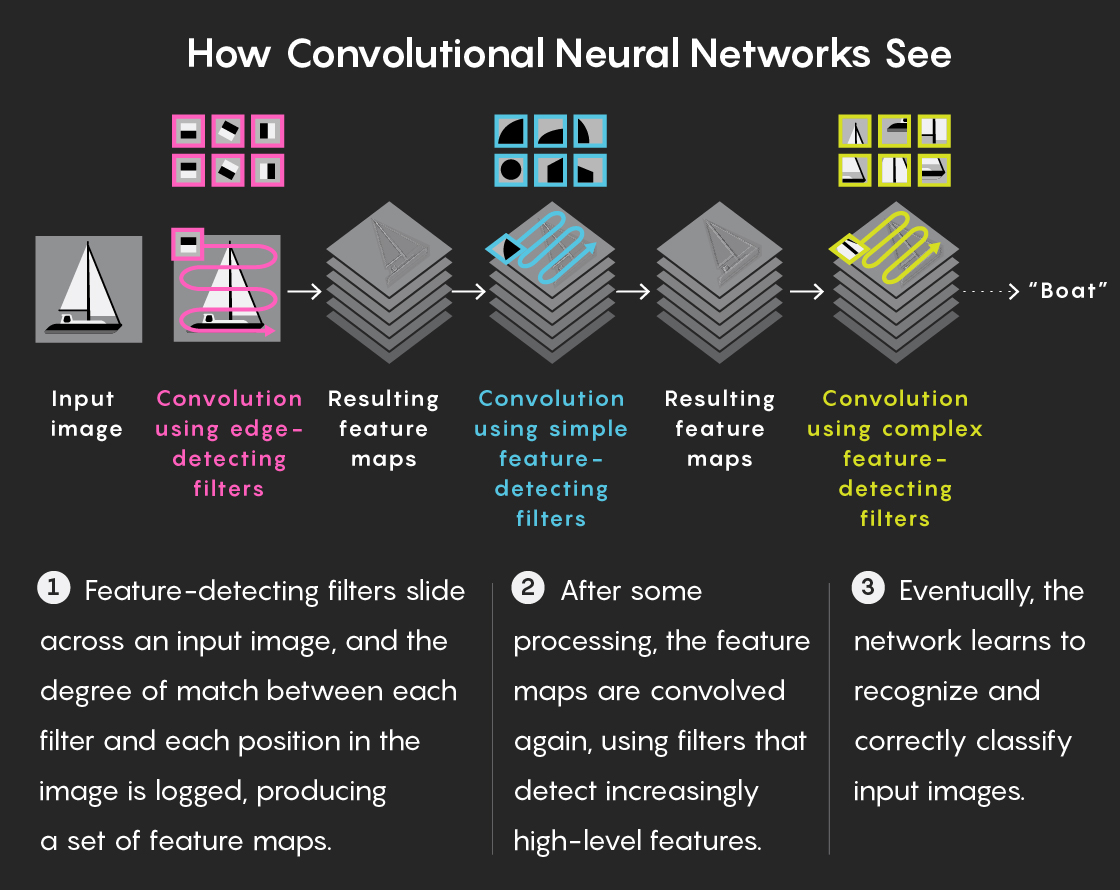
Bronstein and his collaborators knew that going beyond the Euclidean plane would require them to reimagine one of the basic computational procedures that made neural networks so effective at 2D image recognition in the first place. This procedure, called “convolution,” lets a layer of the neural network perform a mathematical operation on small patches of the input data and then pass the results to the next layer in the network.
“You can think of convolution, roughly speaking, as a sliding window,” Bronstein explained. A convolutional neural network slides many of these “windows” over the data like filters, with each one designed to detect a certain kind of pattern in the data. In the case of a cat photo, a trained CNN may use filters that detect low-level features in the raw input pixels, such as edges. These features are passed up to other layers in the network, which perform additional convolutions and extract higher-level features, like eyes, tails or triangular ears. A CNN trained to recognize cats will ultimately use the results of these layered convolutions to assign a label — say, “cat” or “not cat” — to the whole image.
Lucy Reading-Ikkanda/Quanta Magazine
But that approach only works on a plane. “As the surface on which you want to do your analysis becomes curved, then you’re basically in trouble,” said Welling.
Performing a convolution on a curved surface — known in geometry as a manifold — is much like holding a small square of translucent graph paper over a globe and attempting to accurately trace the coastline of Greenland. You can’t press the square onto Greenland without crinkling the paper, which means your drawing will be distorted when you lay it flat again. But holding the square of paper tangent to the globe at one point and tracing Greenland’s edge while peering through the paper (a technique known as Mercator projection) will produce distortions too. Alternatively, you could just place your graph paper on a flat world map instead of a globe, but then you’d just be replicating those distortions — like the fact that the entire top edge of the map actually represents only a single point on the globe (the North Pole). And if the manifold isn’t a neat sphere like a globe, but something more complex or irregular like the 3D shape of a bottle, or a folded protein, doing convolution on it becomes even more difficult.
Bronstein and his collaborators found one solution to the problem of convolution over non-Euclidean manifolds in 2015, by reimagining the sliding window as something shaped more like a circular spiderweb than a piece of graph paper, so that you could press it against the globe (or any curved surface) without crinkling, stretching or tearing it.
Changing the properties of the sliding filter in this way made the CNN much better at “understanding” certain geometric relationships. For example, the network could automatically recognize that a 3D shape bent into two different poses — like a human figure standing up and a human figure lifting one leg — were instances of the same object, rather than two completely different objects. The change also made the neural network dramatically more efficient at learning. Standard CNNs “used millions of examples of shapes [and needed] training for weeks,” Bronstein said. “We used something like 100 shapes in different poses and trained for maybe half an hour.”
At the same time, Taco Cohen and his colleagues in Amsterdam were beginning to approach the same problem from the opposite direction. In 2015, Cohen, a graduate student at the time, wasn’t studying how to lift deep learning out of flatland. Rather, he was interested in what he thought was a practical engineering problem: data efficiency, or how to train neural networks with fewer examples than the thousands or millions that they often required. “Deep learning methods are, let’s say, very slow learners,” Cohen said. This poses few problems if you’re training a CNN to recognize, say, cats (given the bottomless supply of cat images on the internet). But if you want the network to detect something more important, like cancerous nodules in images of lung tissue, then finding sufficient training data — which needs to be medically accurate, appropriately labeled, and free of privacy issues — isn’t so easy. The fewer examples needed to train the network, the better.
Cohen knew that one way to increase the data efficiency of a neural network would be to equip it with certain assumptions about the data in advance — like, for instance, that a lung tumor is still a lung tumor, even if it’s rotated or reflected within an image. Usually, a convolutional network has to learn this information from scratch by training on many examples of the same pattern in different orientations. In 2016, Cohen and Welling co-authored a paper defining how to encode some of these assumptions into a neural network as geometric symmetries. This approach worked so well that by 2018, Cohen and co-author Marysia Winkels had generalized it even further, demonstrating promising results on recognizing lung cancer in CT scans: Their neural network could identify visual evidence of the disease using just one-tenth of the data used to train other networks.
The Amsterdam researchers kept on generalizing. That’s how they found their way to gauge equivariance.
Extending Equivariance
Physics and machine learning have a basic similarity. As Cohen put it, “Both fields are concerned with making observations and then building models to predict future observations.” Crucially, he noted, both fields seek models not of individual things — it’s no good having one description of hydrogen atoms and another of upside-down hydrogen atoms — but of general categories of things. “Physics, of course, has been quite successful at that.”
Equivariance (or “covariance,” the term that physicists prefer) is an assumption that physicists since Einstein have relied on to generalize their models. “It just means that if you’re describing some physics right, then it should be independent of what kind of ‘rulers’ you use, or more generally what kind of observers you are,” explained Miranda Cheng, a theoretical physicist at the University of Amsterdam who wrote a paper with Cohen and others exploring the connections between physics and gauge CNNs. Or as Einstein himself put it in 1916: “The general laws of nature are to be expressed by equations which hold good for all systems of coordinates.”
Convolutional networks became one of the most successful methods in deep learning by exploiting a simple example of this principle called “translation equivariance.” A window filter that detects a certain feature in an image — say, vertical edges — will slide (or “translate”) over the plane of pixels and encode the locations of all such vertical edges; it then creates a “feature map” marking these locations and passes it up to the next layer in the network. Creating feature maps is possible because of translation equivariance: The neural network “assumes” that the same feature can appear anywhere in the 2D plane and is able to recognize a vertical edge as a vertical edge whether it’s in the upper right corner or the lower left.
“The point about equivariant neural networks is [to] take these obvious symmetries and put them into the network architecture so that it’s kind of free lunch,” Weiler said.
By 2018, Weiler, Cohen and their doctoral supervisor Max Welling had extended this “free lunch” to include other kinds of equivariance. Their “group-equivariant” CNNs could detect rotated or reflected features in flat images without having to train on specific examples of the features in those orientations; spherical CNNs could create feature maps from data on the surface of a sphere without distorting them as flat projections.
These approaches still weren’t general enough to handle data on manifolds with a bumpy, irregular structure — which describes the geometry of almost everything, from potatoes to proteins, to human bodies, to the curvature of space-time. These kinds of manifolds have no “global” symmetry for a neural network to make equivariant assumptions about: Every location on them is different.
Lucy Reading-Ikkanda/Quanta Magazine
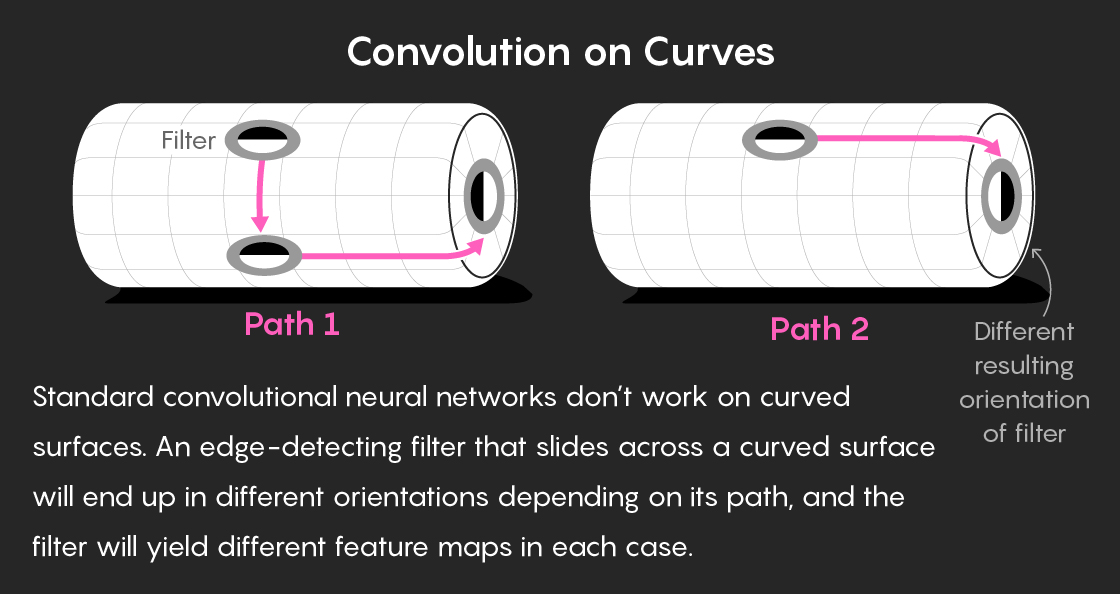
The challenge is that sliding a flat filter over the surface can change the orientation of the filter, depending on the particular path it takes. Imagine a filter designed to detect a simple pattern: a dark blob on the left and a light blob on the right. Slide it up, down, left or right on a flat grid, and it will always stay right-side up. But even on the surface of a sphere, this changes. If you move the filter 180 degrees around the sphere’s equator, the filter’s orientation stays the same: dark blob on the left, light blob on the right. However, if you slide it to the same spot by moving over the sphere’s north pole, the filter is now upside down — dark blob on the right, light blob on the left. The filter won’t detect the same pattern in the data or encode the same feature map. Move the filter around a more complicated manifold, and it could end up pointing in any number of inconsistent directions.
Luckily, physicists since Einstein have dealt with the same problem and found a solution: gauge equivariance.
The key, explained Welling, is to forget about keeping track of how the filter’s orientation changes as it moves along different paths. Instead, you can choose just one filter orientation (or gauge), and then define a consistent way of converting every other orientation into it.
The catch is that while any arbitrary gauge can be used in an initial orientation, the conversion of other gauges into that frame of reference must preserve the underlying pattern — just as converting the speed of light from meters per second into miles per hour must preserve the underlying physical quantity. With this gauge-equivariant approach, said Welling, “the actual numbers change, but they change in a completely predictable way.”
Cohen, Weiler and Welling encoded gauge equivariance — the ultimate “free lunch” — into their convolutional neural network in 2019. They did this by placing mathematical constraints on what the neural network could “see” in the data via its convolutions; only gauge-equivariant patterns were passed up through the network’s layers. “Basically you can give it any surface” — from Euclidean planes to arbitrarily curved objects, including exotic manifolds like Klein bottles or four-dimensional space-time — “and it’s good for doing deep learning on that surface,” said Welling.
A Working Theory
The theory of gauge-equivariant CNNs is so generalized that it automatically incorporates the built-in assumptions of previous geometric deep learning approaches — like rotational equivariance and shifting filters on spheres. Even Michael Bronstein’s earlier method, which let neural networks recognize a single 3D shape bent into different poses, fits within it. “Gauge equivariance is a very broad framework. It contains what we did in 2015 as particular settings,” Bronstein said.
A gauge CNN would theoretically work on any curved surface of any dimensionality, but Cohen and his co-authors have tested it on global climate data, which necessarily has an underlying 3D spherical structure. They used their gauge-equivariant framework to construct a CNN trained to detect extreme weather patterns, such as tropical cyclones, from climate simulation data. In 2017, government and academic researchers used a standard convolutional network to detect cyclones in the data with 74% accuracy; last year, the gauge CNN detected the cyclones with 97.9% accuracy. (It also outperformed a less general geometric deep learning approach designed in 2018 specifically for spheres — that system was 94% accurate.)
Mayur Mudigonda, a climate scientist at Lawrence Berkeley National Laboratory who uses deep learning, said he’ll continue to pay attention to gauge CNNs. “That aspect of human visual intelligence” — spotting patterns accurately regardless of their orientation — “is what we’d like to translate into the climate community,” he said. Qualcomm, a chip manufacturer which recently hired Cohen and Welling and acquired a startup they built incorporating their early work in equivariant neural networks, is now planning to apply the theory of gauge CNNs to develop improved computer vision applications, like a drone that can “see” in 360 degrees at once. (This fish-eye view of the world can be naturally mapped onto a spherical surface, just like global climate data.)
Meanwhile, gauge CNNs are gaining traction among physicists like Cranmer, who plans to put them to work on data from simulations of subatomic particle interactions. “We’re analyzing data related to the strong [nuclear] force, trying to understand what’s going on inside of a proton,” Cranmer said. The data is four-dimensional, he said, “so we have a perfect use case for neural networks that have this gauge equivariance.”
Risi Kondor, a former physicist who now studies equivariant neural networks, said the potential scientific applications of gauge CNNs may be more important than their uses in AI.
“If you are in the business of recognizing cats on YouTube and you discover that you’re not quite as good at recognizing upside-down cats, that’s not great, but maybe you can live with it,” he said. But for physicists, it’s crucial to ensure that a neural network won’t misidentify a force field or particle trajectory because of its particular orientation. “It’s not just a matter of convenience,” Kondor said — “it’s essential that the underlying symmetries be respected.”
But while physicists’ math helped inspire gauge CNNs, and physicists may find ample use for them, Cohen noted that these neural networks won’t be discovering any new physics themselves. “We’re now able to design networks that can process very exotic kinds of data, but you have to know what the structure of that data is” in advance, he said. In other words, the reason physicists can use gauge CNNs is because Einstein already proved that space-time can be represented as a four-dimensional curved manifold. Cohen’s neural network wouldn’t be able to “see” that structure on its own. “Learning of symmetries is something we don’t do,” he said, though he hopes it will be possible in the future.
Cohen can’t help but delight in the interdisciplinary connections that he once intuited and has now demonstrated with mathematical rigor. “I have always had this sense that machine learning and physics are doing very similar things,” he said. “This is one of the things that I find really marvelous: We just started with this engineering problem, and as we started improving our systems, we gradually unraveled more and more connections.”
Correction: January 9, 2020
The article was revised to note that gauge CNNs were developed at Qualcomm AI Research as well as the University of Amsterdam.
This article was reprinted on Wired.com.



