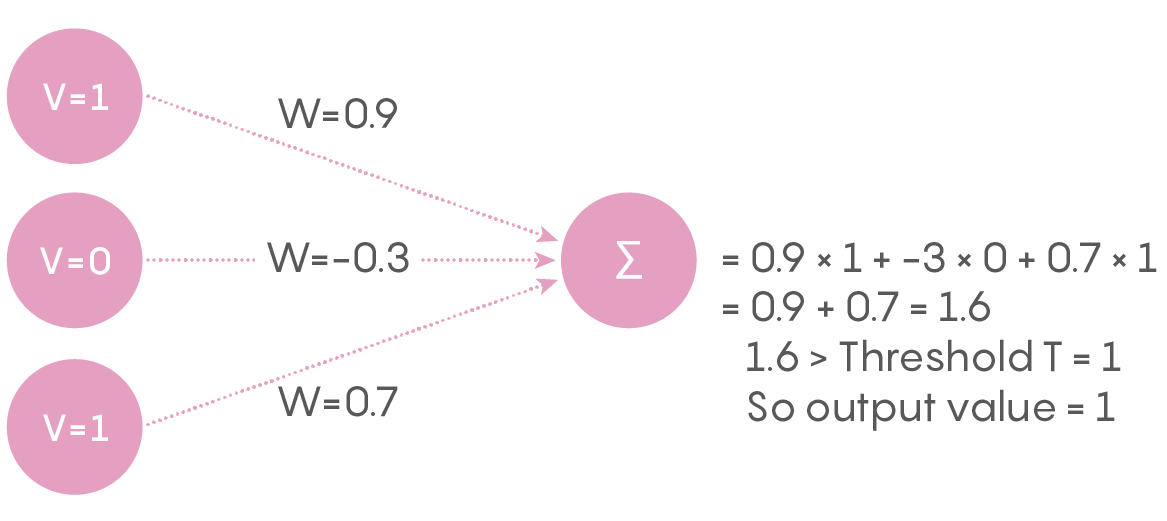When equipped with hidden layers, deep neural networks can accomplish nonlinear feats that are difficult even with sophisticated mathematics.
Read Later
Deep learning promises to make computers far better at tasks like facial recognition, image understanding and machine translation. Our October puzzle asked you to play with simple artificial neural networks to explore the phenomenon of deep learning and gain some insight into how it has achieved such spectacular successes in the field of artificial intelligence.
Problem 1
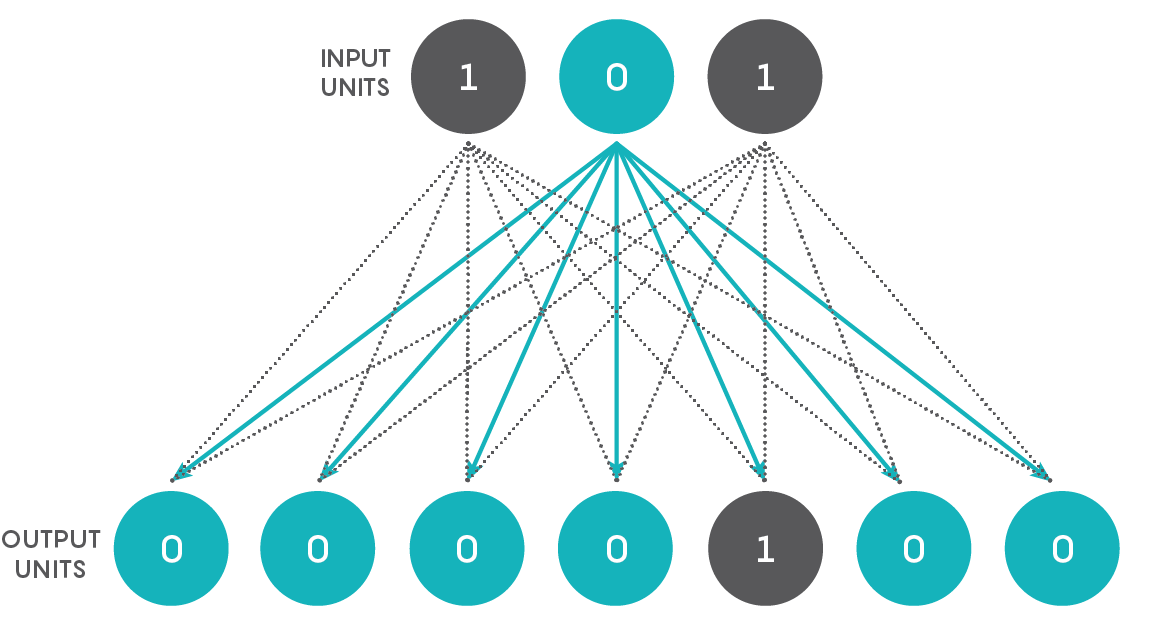
We’re going to create a simple network that converts binary numbers to decimal numbers. Imagine a network with just two layers: an input layer consisting of three units and an output layer with seven units. Each unit in the first layer connects to each unit in the second, as shown in the figure below.
As you can see, there are 21 connections. Every unit in the input layer, at a given point in time, is either off or on, having a value of 0 or 1. Every connection from the input layer to the output layer has an associated weight that, in artificial neural networks, is a real number between 0 and 1. Just to be contrary, and to make the network a touch more similar to an actual neural network, let us allow the weight to be a real number between –1 and 1 (the negative sign signifying an inhibitory neuron). The product of the input’s value and the connection’s weight is conveyed to an output unit as shown below. The output unit adds up all the numbers it gets from its connections to obtain a single number, as shown in the figure below using arbitrary input values and connection weights for a single output unit. Based on this number, the output number decides what its state is going to be. If it exceeds a certain threshold, the unit’s value becomes 1, and if not, its value becomes 0. We can call a unit that has a value of 1 a “firing” or “activated” unit and a unit with a value of 0 a “quiescent” unit.
Our three input units from left to right can have the values 001, 010, 011, 100, 101, 110 or 111, which readers may recognize as the binary numbers from 1 through 7.
Now the question: Is it possible to adjust the connection weights and the thresholds of the seven output units so that every binary number input results in the firing of only one appropriate output unit, with all the others being quiescent? The position of the activated output unit should reflect the binary input value. Thus, if the original input is 001, the leftmost output unit (or bottommost when viewed on a phone, as shown in the top figure) alone should fire, whereas if the original input is 101, the output unit that is fifth from the left (or from the bottom on a phone) alone should fire, and so on.
If you think the above result is not possible, try to adjust the weights to get as close as you can. Can you think of a simple adjustment, using additional connections but not additional units, that can improve your answer?
As many readers showed, it is certainly possible to do this — in fact, it is quite simple. Here are some of the solutions that readers found.
Nightrider, Irhum Shafkat, John Smith, Tom Nichols, JR and Hongzhou Lin essentially found the same elegant solution: Assign a unit weight (1 or 0.5) to a connection if the input unit contributes to an output unit and use its negative value (-1 or -0.5), if not. Under this scheme, the input-output weight matrix is as follows:
1
-1
1
-1
1
-1
1
-1
1
1
-1
-1
1
1
-1
-1
-1
1
1
1
1
The rows are the three input units (001, 010 and 100), and the columns are the seven output units (1 through 7). The threshold of an output unit is simply the number of inputs required to make the output unit fire: It is 1 for units 1, 2 and 4; 2 for units 3, 5 and 6; and 3 for unit 7. This problem was simple enough that such solutions can be found by trial and error. For more complicated problems, the formal techniques of matrix mathematics are invaluable in neural network computing, and were demonstrated by all of the above commenters in very sophisticated ways.
A simple and elegant solution was proposed by Russ Abbott. It is similar to the above, but uses a weight of 0.3 for a required input, and -1 for a wrong input. Here too, the output units have thresholds dependent on the number of required units — in this case, 0.3, 0.6 and 0.9. A slightly more difficult problem would have been to require the thresholds to be the same for all the units, as they are in the brain. In this case you would have to adjust the weights themselves based on the number of input units. Here’s a solution matrix of this sort.
1
-0.5
0.5
-0.5
0.5
-1
0.33
-0.5
1
0.5
-0.5
-1
0.5
0.33
-0.5
-0.5
-1
1
0.5
0.5
0.33
In this case, the threshold for all the output units can be set at 2/3.
Problem 2
Now let’s bring in the learning aspect. Assume that the network is in an initial state where every connection weight is 0.5 and every output threshold is 1. The network is then presented with the entire set of all seven input values in serial order (10 times over, if required) and allowed to adjust its weights and thresholds based on the error difference between the observed value and the desired value. As in Problem 1, the connection weights must remain between –1 and 1. Can you create a global, general-purpose learning rule that adjusts the connections and thresholds so that the optimum condition of Problem 1 can be reached or approached? For example, a learning rule could say something like “increase the connection weight by 0.2 within the permitted limits, and decrease its threshold by 0.1, if the output unit remains quiescent in a situation where it should have fired.” You can be as creative as you like with the rule, provided that the specified limits are followed. Note that the rule must be the same for all the units in a given layer and must be general-purpose: It should allow the network to perform better for different sets of inputs and outputs as well.
The general method for solving such problems is called “gradient descent.” Think of the network’s current state as being at the top of a mountain, from which it descends one step at a time in the direction of the desired result: the ground. The idea is simple: You start the network with some set of random weights. You give the network an input, and compare the ideal, correct output with the network’s current output. If it is correct, do nothing. If it is wrong, you find the difference between the ideal output, multiply it by a very small number known as the learning rate (denoted by the Greek letter η, “eta”) and add the product to the weights going into that unit in the direction it needs to go. The specific values that can be used in the current problem and the general rule are explained formally by Tom Nichols, JR and Hongzhou Lin. Generally, there is no guarantee that networks will converge to the best possible solution: The network may get stuck in what is known as a local minimum (think of this as the bottom of a valley in the foothills, rather than the ground). For most simple problems, networks generally converge to very good solutions, if not the perfect ones. For more complex problems, finding the best rules may not be so easy. A recent article in The New York Times titled “Tech Giants Are Paying Huge Salaries for Scarce A.I. Talent” describes the process of creating rules for deep learning: “The basic concepts of deep learning are not hard to grasp, requiring little more than high-school-level math. But real expertise requires more significant math and an intuitive talent that some call ‘a dark art.’”
In our case, this very simple network can very easily solve the problem posed. In fact, we do not need to use a network with hidden layers at all. What then is the limitation of such simple networks? As I described in the puzzle column, the field suffered after Marvin Minsky and Seymour Papert’s criticism of simple networks for a very specific task, which gives us an insight about how such networks work. This insight, which was described by Tom Nichols in the context of this problem, is that single-layer neural networks can be viewed geometrically. Think of neural networks as machines that can classify groups of objects, which can be pictured as being plotted on an XY graph based on numbers that give a measure of two of their properties.
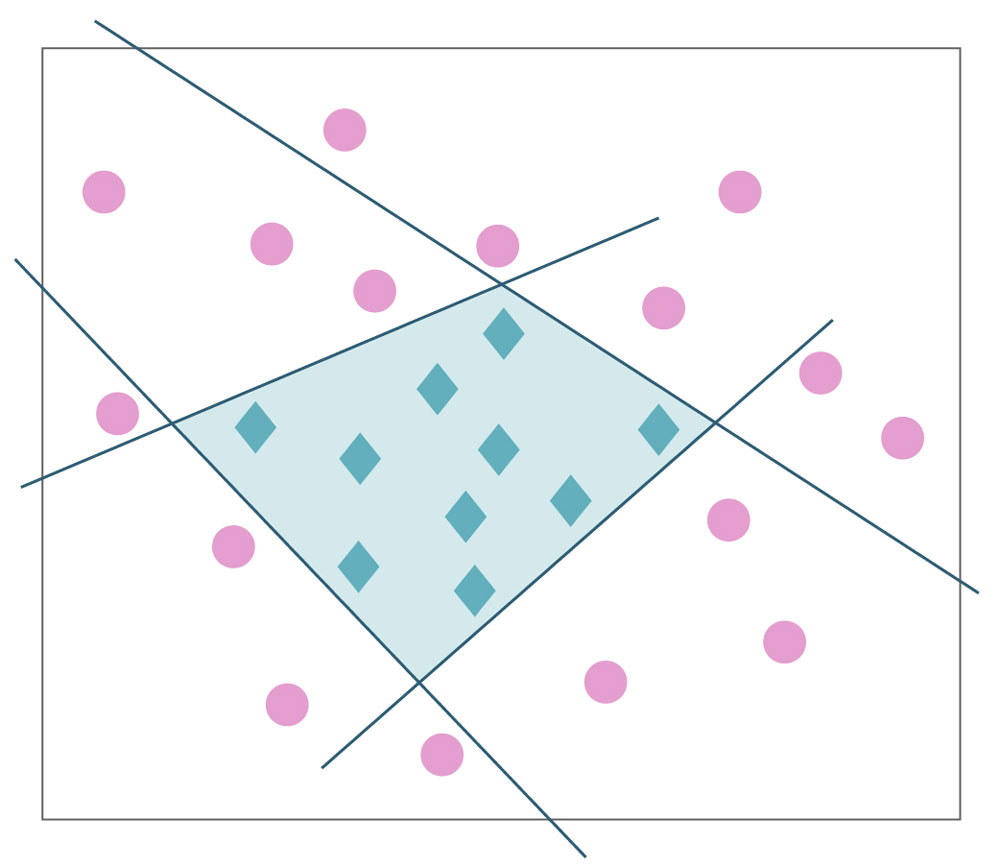
This diagram shows two groups of objects that need to be separated. For many such problems, the groups are “linearly separable” — a simple network without hidden layers can do the job by properly placing a single straight line through the graph. (For problems such as ours, which have multiple inputs and outputs, the number of dimensions increases far beyond the two shown in an XY graph: Squares become “hypercubes” and the line becomes a “hyperplane” as Nichols described. However, the principle of linear separability remains. Nightrider described a linear-programming procedure that can yield the optimal such separating hyperplane in the general case). Many problems can be solved by drawing a single separating line or hyperplane, and therefore by networks like ours. But there are other problems, like the one in the figure above illustrating the famous “XOR problem,” which cannot be solved by simple networks without hidden layers, as Minsky and Papert showed. No single straight line can separate the two groups shown in this figure.
Astute readers will notice, however, that two straight lines can separate the groups. An additional unit in an extra, “hidden” layer in a network can be thought of as giving you the ability to add an additional line. These lines can then be added together or combined in other ways by using more hidden layers.
In the diagram above, one group of objects is completely enclosed by the other group. But a set of four straight lines can separate them, and therefore so can a deep network with hidden layers. You can see how this makes deep networks so powerful: With a bunch of straight lines, you can extract highly mixed groups of any shape, regular or irregular. Thus deep neural networks can do nonlinear feats, which are difficult with even sophisticated mathematics.
Problem 3
Finally, let’s add an extra layer of five units between the input and output layers. Analyzing the resulting three-layer network will probably require computer help, like using a spreadsheet or a simple simulation program. Following the same rules as above, with extra rules for the hidden layer, how does the three-layer network perform on Problems 1 and 2 compared with the two-layer network?
As several commenters noted, an extra layer is not necessary for this problem — the seven outputs are linearly separable. There are technically interesting ways to compute the learning rate for the additional layer, as Hongzhou Lin remarked — skills that are currently of great value in deep learning. Apart from that, though, a three-layer network can discover and generalize other concepts that are hidden in the problem. For instance, the hidden layer of our three-layer network could very well develop nodes that are sensitive to even numbers, odd numbers, numbers less than 4, numbers greater than or equal to 4 and so on. It is quite likely that the complex networks of the human brain develop such neurons that generalize similar properties of real-world data in the process of solving specific problems. No doubt, this gives human intelligence its immense flexibility.
The comments to this puzzle were excellent and very sophisticated. Some of the commenters were obviously experts and highly trained. I’d like to specifically mention nightrider, Tom Nichols, JR and Hongzhou Lin in this regard. From the point of view of a puzzle column, we also enjoy simple elegant solutions like those provided by nightrider, Irhum Shafkat, John Smith and Russ Abbott, which can be appreciated by those without formidable technical skills.
While Tom Nichols, JR and Hongzhou Lin submitted excellent solutions for all the problems, only one person can win the Quanta T-shirt for October. That goes to nightrider for comments that appealed to both categories of comments described above.
Thank you all for your contributions. See you soon for new insights.
The Quanta Newsletter
Get highlights of the most important news delivered to your email inbox
Quanta Magazine moderates comments to facilitate an informed, substantive, civil conversation. Abusive, profane, self-promotional, misleading, incoherent or off-topic comments will be rejected. Moderators are staffed during regular business hours (New York time) and can only accept comments written in English.
Next article
Life’s First Molecule Was Protein, Not RNA, New Model Suggests
Log in to Quanta
Use your social network
or
Don't have an account yet?
Sign up
Forgot your password?
We’ll email you instructions to reset your password