What's up in
Graph theory
Latest Articles
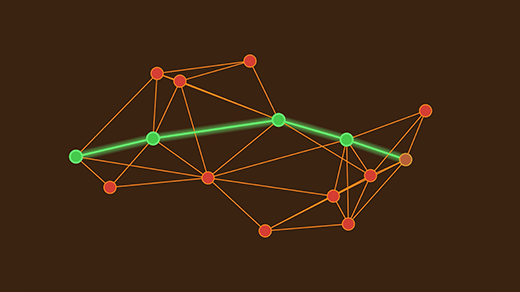
Computer Scientists Establish the Best Way to Traverse a Graph
Dijkstra’s algorithm was long thought to be the most efficient way to find a graph’s best routes. Researchers have now proved that it’s “universally optimal.”
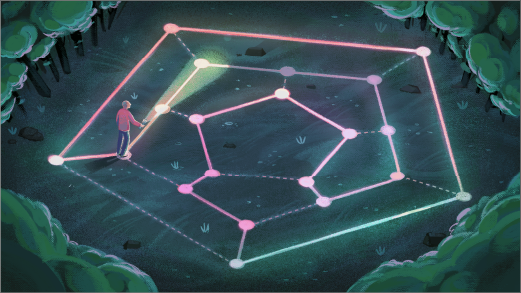
In Highly Connected Networks, There’s Always a Loop
Mathematicians show that graphs of a certain common type must contain a route that visits each point exactly once.

To Pack Spheres Tightly, Mathematicians Throw Them at Random
Four mathematicians broke a 75-year-old record by finding a denser way to pack high-dimensional spheres.

Topologists Tackle the Trouble With Poll Placement
Mathematicians are using topological abstractions to find places where it’s hard to vote.

Maze Proof Establishes a ‘Backbone’ for Statistical Mechanics
Four mathematicians have estimated the chances that there’s a clear path through a random maze.

The Year in Math
Landmark results in Ramsey theory and a remarkably simple aperiodic tile capped a year of mathematical delight and discovery.

A Close-Up View Reveals the ‘Melting’ Point of an Infinite Graph
Just as ice melts to water, graphs undergo phase transitions. Two mathematicians showed that they can pinpoint such transitions by examining only local structure.

New Proof Shows That ‘Expander’ Graphs Synchronize
The proof establishes new conditions that cause connected oscillators to sway in sync.

Math That Lets You Think Locally but Act Globally
Knowing a little about the local connections on flight maps and other networks can reveal a lot about a system’s global structure.